Understand scope
Understanding the concept of query scope in Scuba is important to understanding exactly how Scuba derives query results. This article describes:
what we mean by query scope,
how changes in query scope affect how results are calculated, and
how to apply knowledge of query scope to construct and interpret queries in Scuba.
We begin with a definition of scope. We then inspect each of the scopes (event, actor, and flow) in Scuba. Finally, we discuss how a query that references multiple types of properties (event, actor, or flow) interprets those properties so that properties of a different type fit into the query scope.
This article provides example queries, accompanied by explanations of how the queries are calculated. The goal of these explanations is not to describe the exact calculations Scuba performs to arrive at the example result, but to provide a mental model for Scuba users that wish to understand the role scope plays in the query calculation. This article does not cover topics like merging results from the distributed data tier, scaling sampled queries, or performance optimizations. In some cases the exact order of operations might be slightly different or asynchronous, but the results will be the same as if the query followed the described order of operations exactly.
Query scope: a general definition
In general, every Scuba query or measure involves some sort of aggregation. Here are some aggregations (with example context) that you can specify in Scuba:
count unique users that viewed the support page
average session durations for Android devices
sum play time per music service
The scope of a query refers to the type of entity an aggregation in Scuba iterates over to produce a result. An aggregation can iterate over events, actors, or flows. It follows that Scuba's three query scopes are called event scope, actor scope, and flow scope.
An example of a query in each scope is as follows:
Scope | Example Query |
Event | count(events) for events where event_name = purchase |
Actor | average(purchases per actor) for actors with at least two purchase events |
Flow | average(session duration) for Android device sessions |
As you can see, counting each individual event is an event scope query, averaging a per-actor value is an actor scope query, and averaging a per-session value is a flow scope query. When computing these query results, Scuba iterates over event, actors, and flows, respectively.
Scuba automatically determines the scope of a query by inspecting query arguments. If a query is averaging something that is calculated on a per-actor basis, it is highly likely that the scope of that query is actor scope.
With that, let's study each individual scope.
The scopes of Scuba queries
In this section, we investigate each query scope independently.
To do so, consider queries on a simple 10 event dataset. Here are the exact events that would have been ingested into Scuba for the following examples:
{"user":"John","ts":"2020-01-25T12:00:00Z","action":"login","latency":43}{"user":"John","ts":"2020-01-25T12:01:00Z","action":"read","latency":11}{"user":"John","ts":"2020-01-25T12:02:00Z","action":"post","latency":25}{"user":"Anca","ts":"2020-01-25T13:00:00Z","action":"read","latency":12}{"user":"Anca","ts":"2020-01-25T13:01:00Z","action":"post","latency":27}{"user":"Anca","ts":"2020-01-25T13:02:00Z","action":"post","latency":29}{"user":"Manasa","ts":"2020-01-25T14:00:00Z","action":"read","latency":9}{"user":"Manasa","ts":"2020-01-25T14:01:00Z","action":"read","latency":121}{"user":"Manasa","ts":"2020-01-25T15:00:00Z","action":"read","latency":9}{"user":"Manasa","ts":"2020-01-25T15:01:32Z","action":"post","latency":28}
Event scope
A Scuba query in event scope iterates directly over the events imported to a Scuba table (also known as a dataset).
You can visualize the data aggregated over in an event scope query as a spreadsheet or relational database table, with one row per event, and each column corresponding to either a raw event property imported directly from the source data, or a manual event property created in Scuba. For instance, you can visualize event scope for a query in our sample dataset as (where is_high_latency_read is a user-created manual event property that returns true if action == read and latency >= 100):
user | ts | action | latency | is_high_latency_read |
John | 2020-01-25T12:00:00Z | login | 43 | false |
John | 2020-01-25T12:01:00Z | read | 11 | false |
John | 2020-01-25T12:02:00Z | post | 25 | false |
Anca | 2020-01-25T13:00:00Z | read | 12 | false |
Anca | 2020-01-25T13:01:00Z | post | 27 | false |
Anca | 2020-01-25T13:02:00Z | post | 29 | false |
Manasa | 2020-01-25T14:00:00Z | read | 9 | false |
Manasa | 2020-01-25T14:01:00Z | read | 121 | true |
Manasa | 2020-01-25T15:00:00Z | read | 9 | false |
Manasa | 2020-01-25T15:01:32Z | post | 28 | false |
In an actual query, Scuba loads only the columns that are used in the query to perform the calculation. The table above represents the data iterated over only if the event scope query accesses all of the columns and manual event property. For example, in a simple average(latency) query, Scuba loads only the latency column (still one row per event) to produce the result.
With this table in mind, we can now think about aggregating over the rows (events) in the table in order to produce a query result.
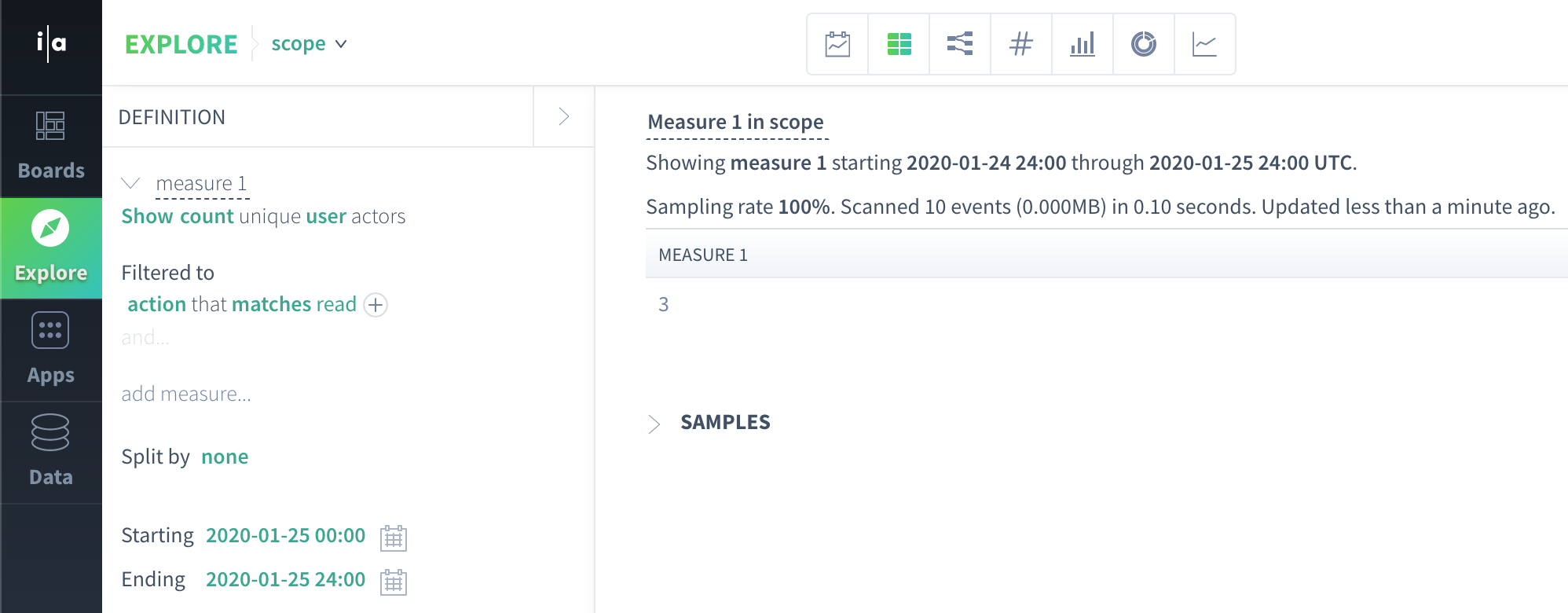
Let's do so now, answering the question how many unique users did a read action on 2020-01-25? using an event scope approach.
First, since this query relies on the user and action event properties, we can visualize the data we iterate over to produce the result as a table with two columns (representing the user and action event property values) and 10 rows (one row for each event because this query is in event scope):
user | action |
John | login |
John | read |
John | post |
Anca | read |
Anca | post |
Anca | post |
Manasa | read |
Manasa | read |
Manasa | read |
Manasa | post |
Also, since we applied a filter for our events, we can filter to just the events where action == read:
user | action |
John | read |
Anca | read |
Manasa | read |
Manasa | read |
Manasa | read |
Finally, we can apply our count_unique(user) aggregation over these events to produce our result:
count_unique("John","Anca","Manasa","Manasa","Manasa") = 3The key takeaway here is that our count unique aggregation iterated over events to produce the result. Iterating over events is what makes a query event scope.
Here is what the event scope query in our example looks like in the Scuba UI:
Actor scope
A Scuba query in actor scope iterates over the actors contained within the Scuba table, or dataset. Unlike in event scope, the actor-based tables that an actor scope query iterates over are not stored on disk or generated during the Scuba import process. Instead, Scuba produces an actor-based table from a subquery over the event data, and then produces results from the actor-based table.
We can answer the question posed in the event scope section how many unique users did a read action on 2020-01-25? by issuing an actor scope query instead of an event scope query. Let's see what that looks like.
First, we need to instruct Scuba to produce data in the actor scope that we can iterate over. We do this by creating an actor property. To answer the question, we create an actor property that calculates the number of reads per user. In the Scuba UI that property looks something like this:
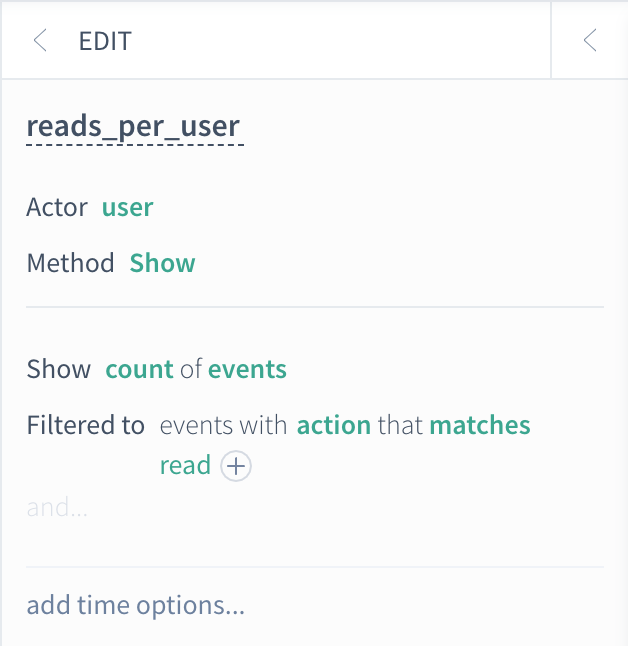
When we use an actor property like this in a query, behind the scenes, Scuba issues a subquery to calculate the per-actor result. The result of this subquery is a (temporary) table in actor scope. We can visualize this similarly to how we visualized the event scope data in the previous section, with one key difference: in actor scope, the data that our aggregation iterates over has one row per actor instead of one row per event.
The subquery that Scuba runs in the case of our reads_per_user actor property is quite simple:
count(events where action = read) split by userThis subquery produces our actor scope data, which in our example looks like this:
user | reads_per_user |
John | 1 |
Anca | 1 |
Manasa | 3 |
From this table, it is easy to produce a query result for our query how many unique users did a read action on 2020-01-25? We can apply a filter to filter to the actor table above on reads_per_user > 0, and then do our unique user aggregation:
count_unique("John","Anca","Manasa") = 3Or, because we are in actor scope where we have one row per actor, we could even answer this with a simple count aggregation as an optimization:
count(per-actor rows where reads_per_user > 0) = 3The key takeaway here is that our final aggregation iterates over actors to produce the result. Iterating over actors is what makes a query actor scope.
Here is what the actor scope query in our example looks like in the Scuba UI:
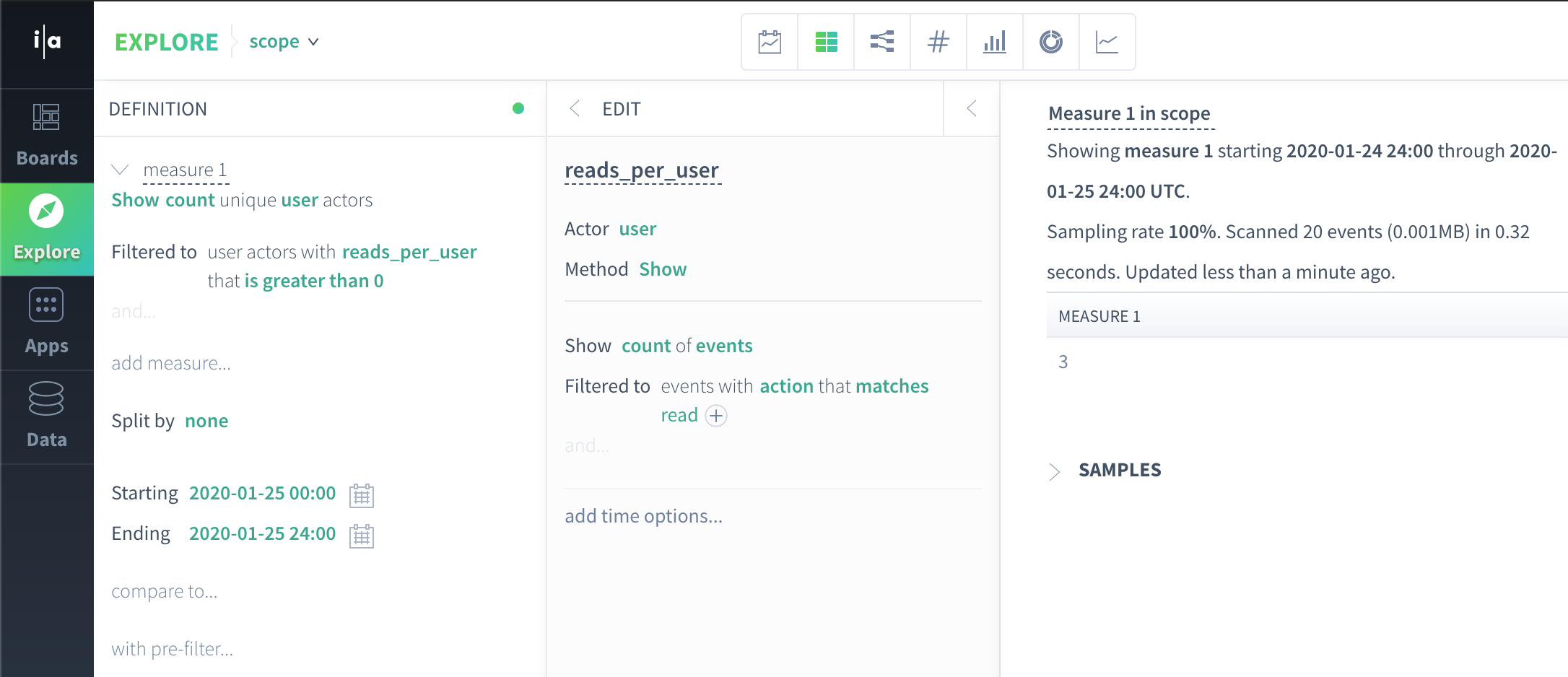
In this particular case, we were able to get to the same result using both actor and event scope queries. The example query we have been investigating was selected intentionally so that we could compare and contrast event and actor scope queries, but leaves much to be desired when it comes to why these different scopes are useful. To help understand this, here are two queries that we can answer using actor scope queries but that are less straightforward (yet not impossible, as we'll see in later sections) to answer in event scope:
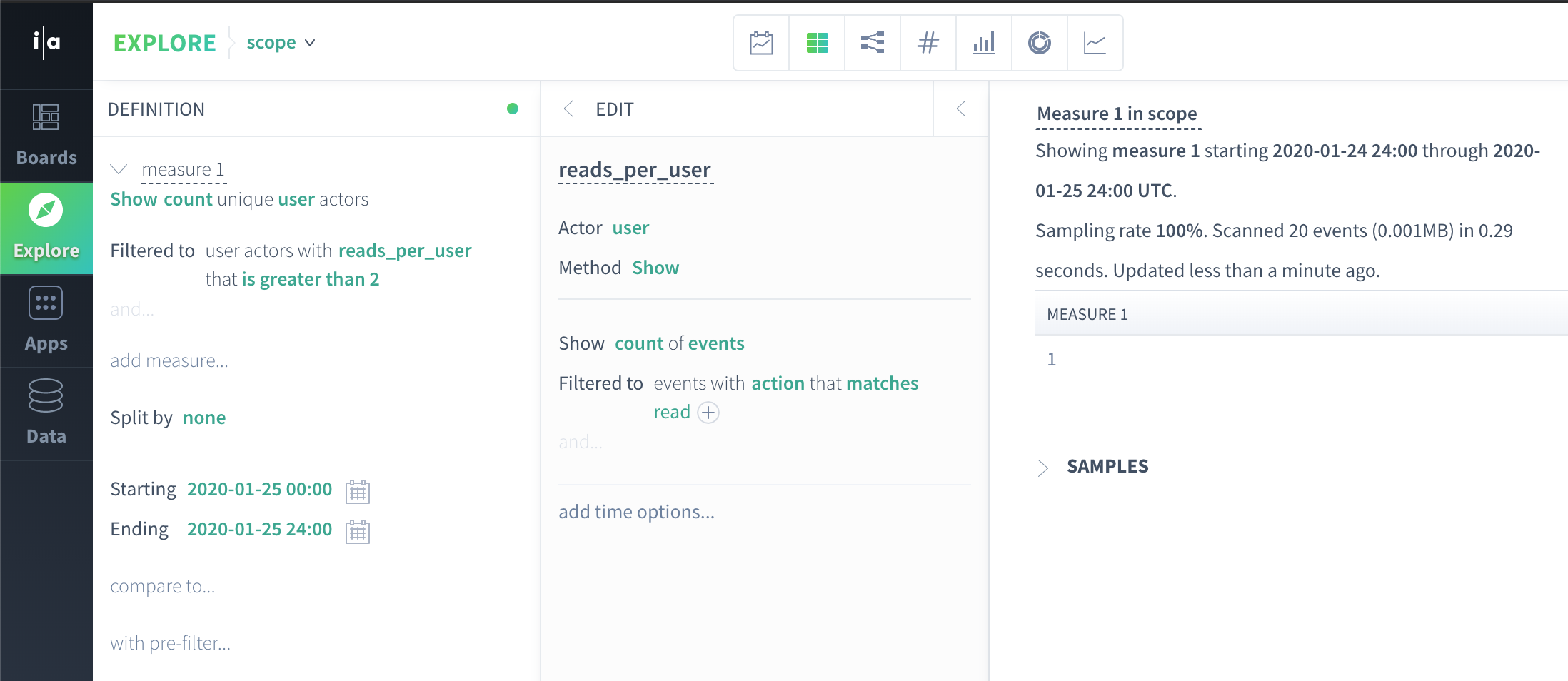
How many unique users did at least 2 read actions on 2020-01-25?
user | reads_per_user |
Manasa | 3 |
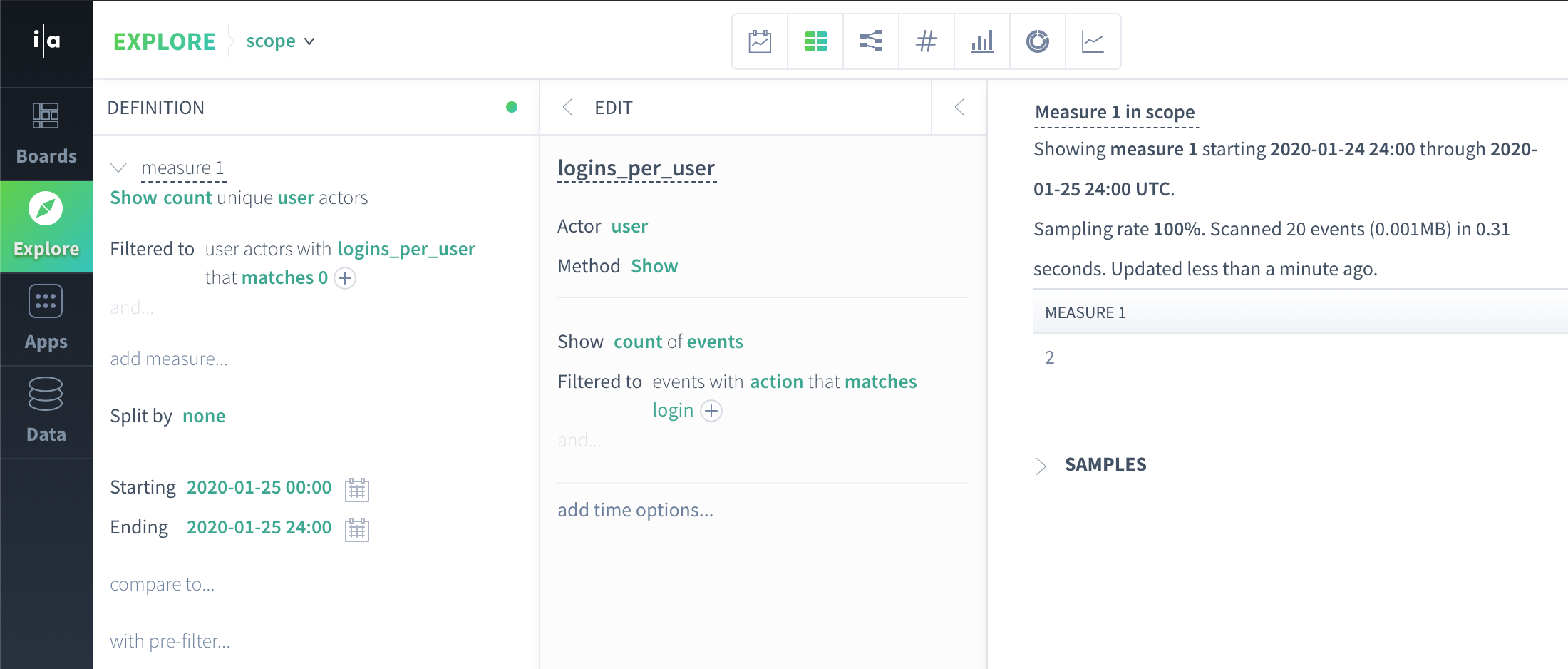
How many unique users did 0 login actions on 2020-01-25 (but did some other kind of event)?
user | logins_per_user |
John | 1 |
Anca | 0 |
Manasa | 0 |
Flow scope
As you have likely now deduced, a Scuba query in flow scope iterates over the flows contained within the Scuba table / dataset. Similarly to actor scope queries, the flow-based tables that a flow scope query iterates over are not stored on disk or generated during the Scuba import process. Instead, Scuba produces a flow-based table from the events imported to Scuba using the logic defined in the flow definition, and then produces results from the flow-based table.
For our flow scope example, we'll use this simple flow that starts and transitions on the first three events of a session as defined by 5 minutes of inactivity:

The count flow instances query that produces the results that the Sankey view displays is flow scope, but for the sake of simplicity we'll run a more straightforward query to illustrate flow scope in action:
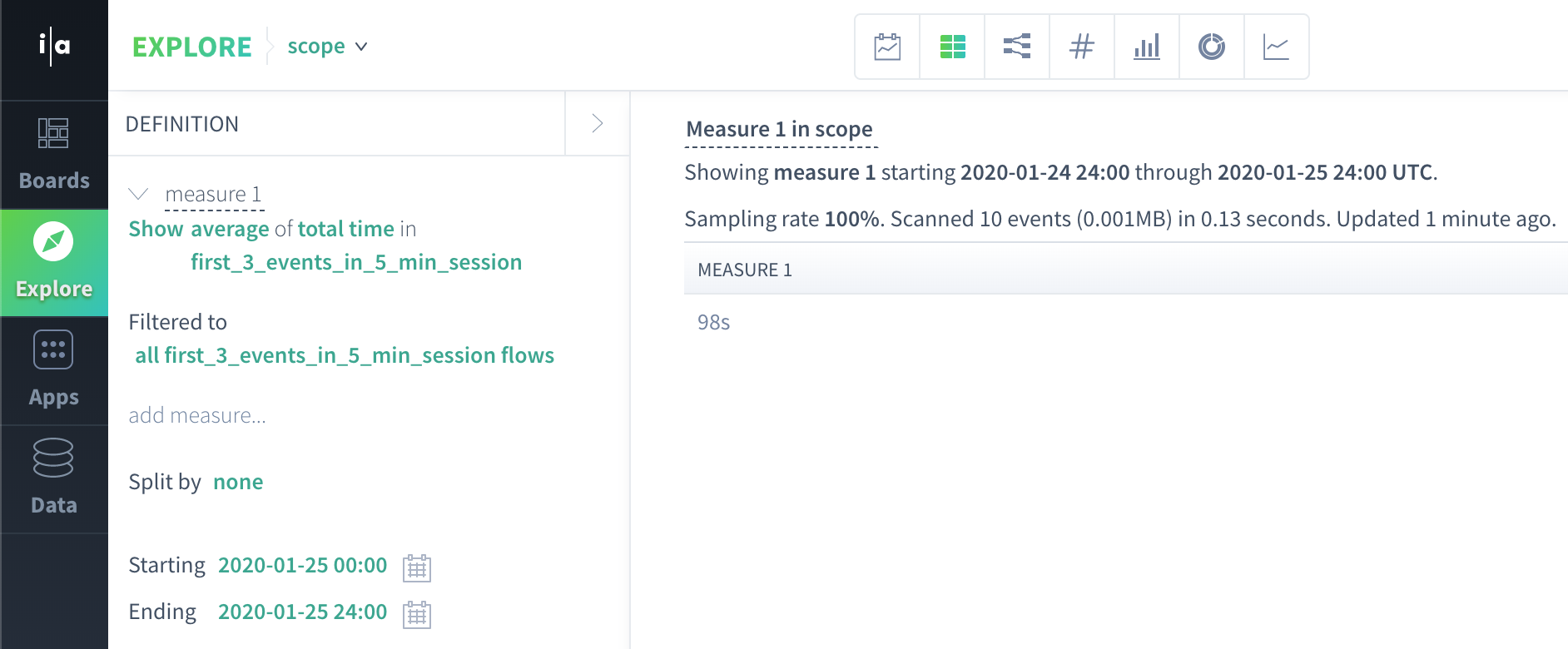
For this query, Scuba produces flow scope data that looks something like this from the 10 raw events ingested into Scuba:
flow_id | user | total_time_in_flow |
1 | John | 120 s |
2 | Anca | 120 s |
3 | Manasa | 60 s |
4 | Manasa | 92 s |
And then to produce our final result, we simply average(120 s, 120 s, 60 s, 92 s) to get an average time of 98 s.
The key takeaway here is that our final aggregation iterates over flows to produce the result. Iterating over flows is what makes a query flow scope.
Resolving scope mismatch
After reading the previous section, hopefully you are gaining confidence in your understanding of the event, actor, and flow scopes of Scuba. With this understanding, we are now equipped to investigate the behavior of Scuba queries when event, actor, and flow properties are combined in the same query.
Recall our model of the actor scope data in the previous section example:
user | reads_per_user |
John | 1 |
Anca | 1 |
Manasa | 3 |
Now imagine adding a filter such as latency(event property) >= 10 to this actor scope query. The event property has a value that varies per event, and the data being iterated over has only a single row for each actor. A single actor can have many values of latency for a given time range! Scuba software cannot automatically combine these two properties. Instead, we need to somehow bring the event property into the actor scope for this query to be valid.
Each time an actor or flow property is referenced in an event scope query, the actor or flow property must be brought into the event scope for the query to make sense. The same goes for an event or flow property in an actor scope query, and an event or actor property in a flow scope query. Scuba often does this automatically, but to fully understand queries that mix these different types of properties, it is important to understand exactly how Scuba resolves these differences in scope.
The following sections detail the ways to resolve these scope mismatches, as well as the Scuba defaults for doing so. For jump links to the appropriate section, see the following matrix:
| Event property | Actor property | Flow property |
Event scope query | No action needed | Bringing actor properties into event scope
| |
Actor scope query | No action needed | ||
Flow scope query | No action needed |
Bringing actor properties into event scope
In Scuba, you can access actor properties in event scope queries by left joining actor scope data (produced by an actor property subquery) to the event scope data on actor. For instance, the following query is an event scope query that references an actor property:
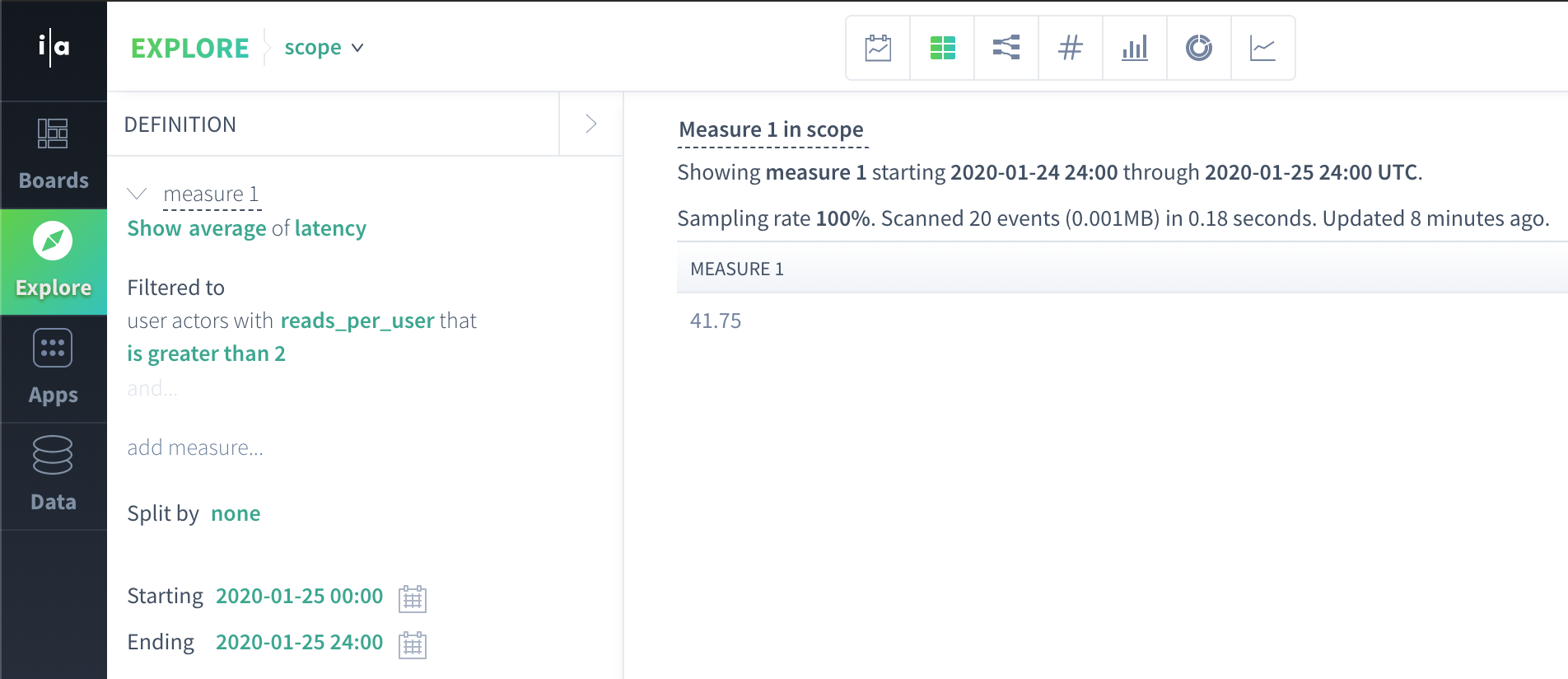
In this query, the user has requested the average(latency) of the events associated with actors who have had more than two read events. Let's apply what we have learned to understand how Scuba calculates this query result.
First, actor scope data is produced by an actor property subquery, as defined in the actor property definition:
user | reads_per_user |
John | 1 |
Anca | 1 |
Manasa | 3 |
Next, the actor scope data is left joined to the event scope data on user:
user | latency | reads_per_user |
John | 43 | 1 |
John | 11 | 1 |
John | 25 | 1 |
Anca | 12 | 1 |
Anca | 27 | 1 |
Anca | 29 | 1 |
Manasa | 9 | 3 |
Manasa | 121 | 3 |
Manasa | 9 | 3 |
Manasa | 28 | 3 |
Scuba filters the events to the events where reads_per_user > 2:
user | latency | reads_per_user |
Manasa | 9 | 3 |
Manasa | 121 | 3 |
Manasa | 9 | 3 |
Manasa | 28 | 3 |
And finally Scuba performs the average(latency) aggregation:
average(9, 121, 9, 28) = 41.75
Bringing flow properties into event scope
Similarly to actor properties, flow properties can be accessed in event scope queries by left joining flow scope data (produced by a flow property subquery) to the event scope data on an internal flow ID. For instance, the following query is an event scope query that references a flow property:
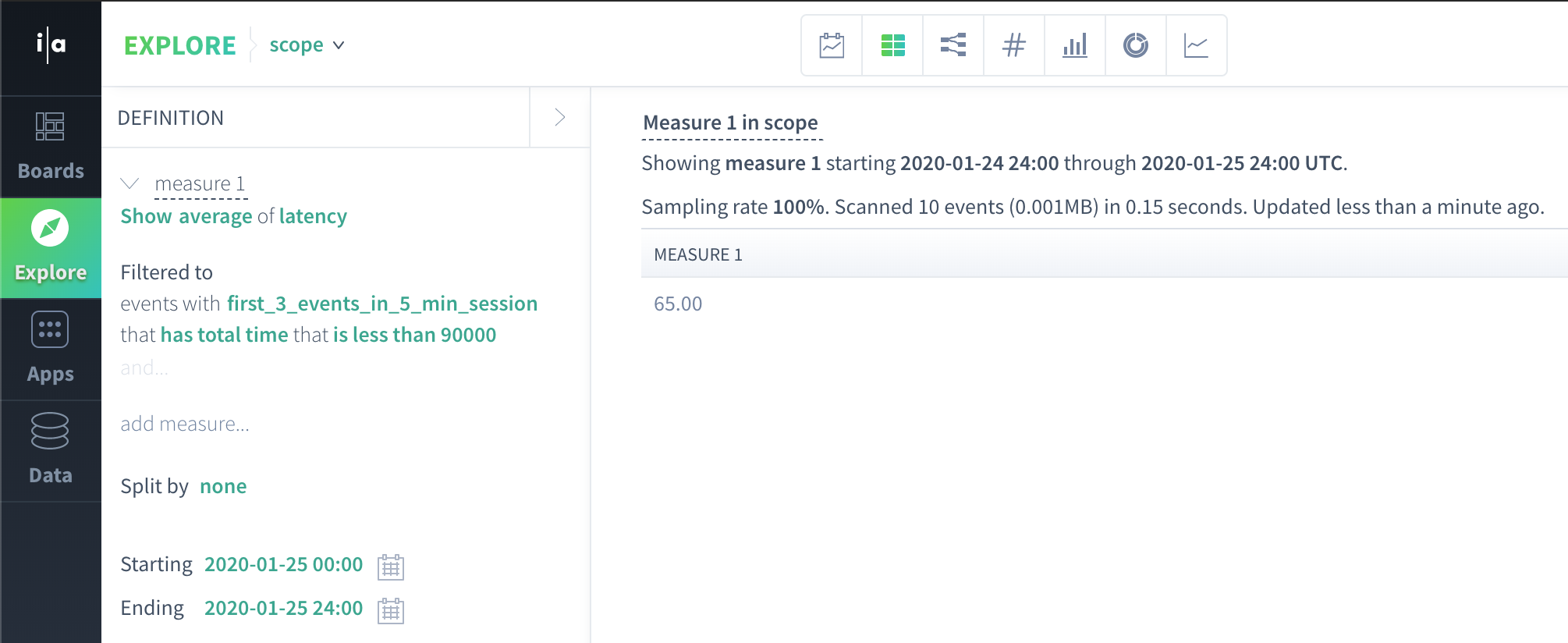
This query produces the average(latency) of events involved in flows that lasted less than 90 seconds. Let's apply what we have learned to understand how this query result is calculated.
First, Scuba produces flow scope data by iterating over events and calculating flows according to the flow definition:
flow_id | user | total_time_in_flow |
1 | John | 120000 |
2 | Anca | 120000 |
3 | Manasa | 60000 |
4 | Manasa | 92000 |
Next, Scuba joins that flow scope data to event scope data in preparation for our event scope aggregation:
user | flow_id | total_time_in_flow | latency |
John | 1 | 120000 | 43 |
John | 1 | 120000 | 11 |
John | 1 | 120000 | 25 |
Anca | 2 | 120000 | 12 |
Anca | 2 | 120000 | 27 |
Anca | 2 | 120000 | 29 |
Manasa | 3 | 60000 | 9 |
Manasa | 3 | 60000 | 121 |
Manasa | 4 | 92000 | 9 |
Manasa | 4 | 92000 | 28 |
Scuba then applies the filter to our events:
user | flow_id | total_time_in_flow | latency |
Manasa | 3 | 60000 | 9 |
Manasa | 3 | 60000 | 121 |
Finally, Scuba performs an event scope aggregation to product the desired result:
average(9, 121) = 65
For instructions on using a flow property in an event scope query, see Query on stages in a flow.
Bringing event properties into actor scope
A common use case for Scuba queries is to reference event properties in actor scope queries. Bringing an event property into actor scope is a bit more complicated than the other way around, because there are several valid ways to bring an event property into actor scope (instead of a simple left join). The correct way to go about doing this depends on the question you are trying to answer.
The ways to do this fall into two categories: an event property can be brought into actor scope by creating an actor property from that event property, or existing actor properties in the actor scope can be modified to include the event property in their definitions.
For example, imagine we have the following actor scope query:
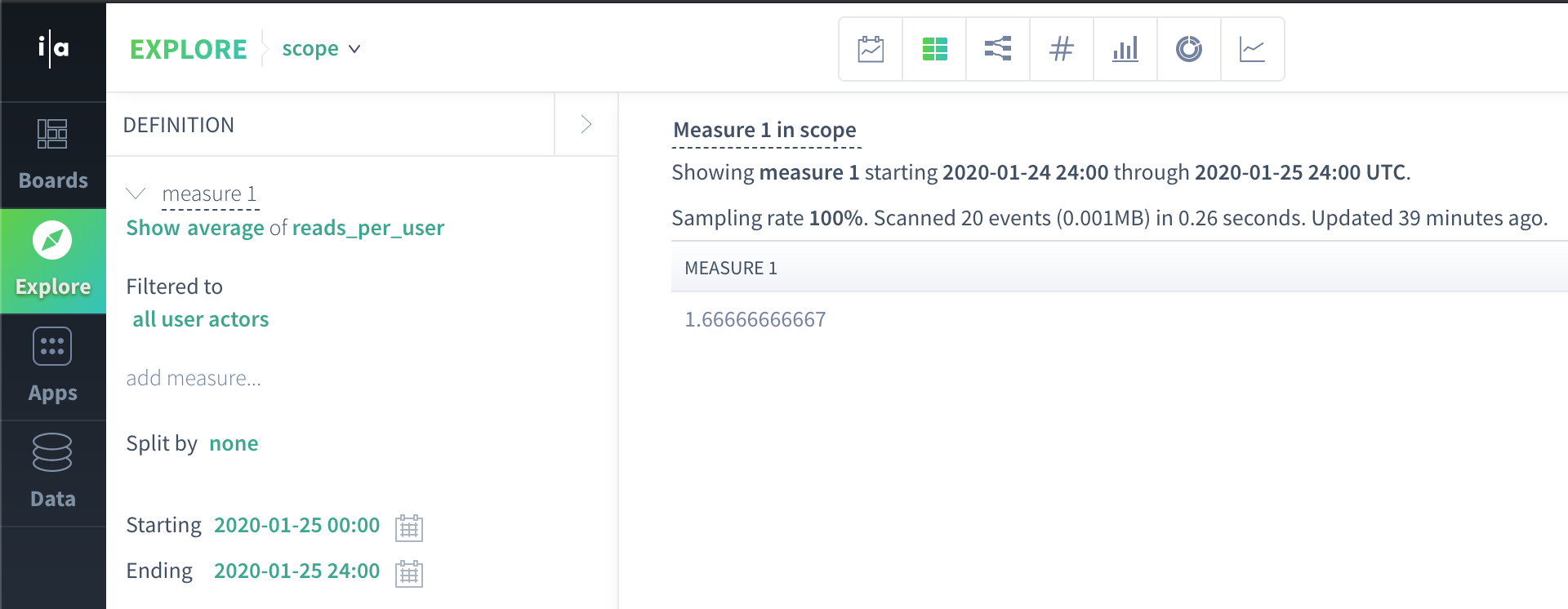
Often Scuba analysts want to apply an event property filter to a query like this, such as latency >= 50. At this point, there are multiple reasonable queries that could result from adding a latency >= 50 filter to such a query. For instance:
what is the average per-user read count for users with at least one high latency event on 2020-01-25?
what is the average per-user read count for users with at least one high latency event in that user's entire lifetime?
what is the average per-user read count for users whose median latency over all events on 2020-01-25 >= 50?
what is the average per-user high latency read count on 2020-01-25?
All of the above queries are valid interpretations of adding a latency >= 50 filter to an average(reads_per_user) actor scope query. All of these queries can be answered in Scuba by either creating an actor property from the event property (Queries 1, 2, and 3) or modifying the existing actor property (Query 4).
You can do this by creating or altering the properties manually. Let's do so now for the four queries above.
Query 1: What is the average per-user read count for users with at least one high latency event on 2020-01-25?
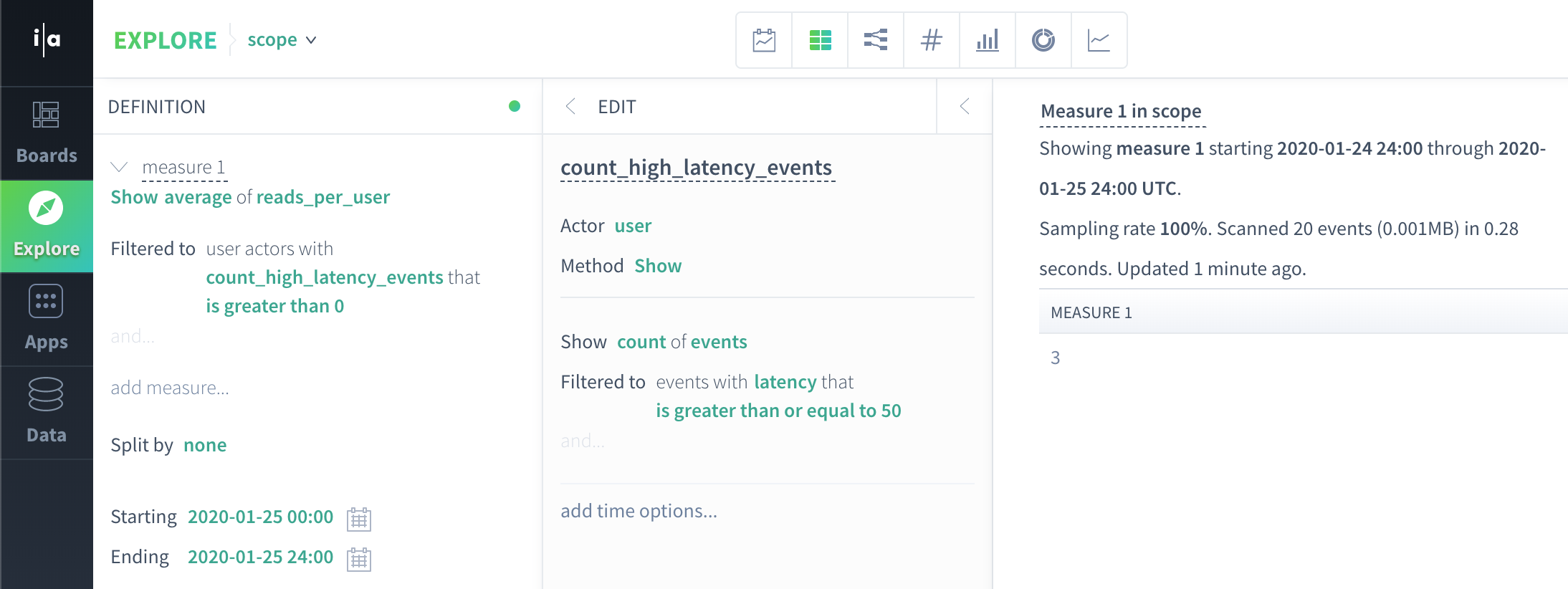
First, we produce actor scope data with a subquery that produces reads_per_user and count_high_latency_events columns:
user | reads_per_user | count_high_latency_events |
John | 1 | 0 |
Anca | 1 | 0 |
Manasa | 3 | 1 |
Next, we filter to actors that satisfy the condition set in the filter:
user | reads_per_user | count_high_latency_events |
Manasa | 3 | 1 |
Finally, we average(reads_per_user):
average(3) = 3.
Query 2: What is the average per-user read count for users with at least one high latency event in that user's entire lifetime?
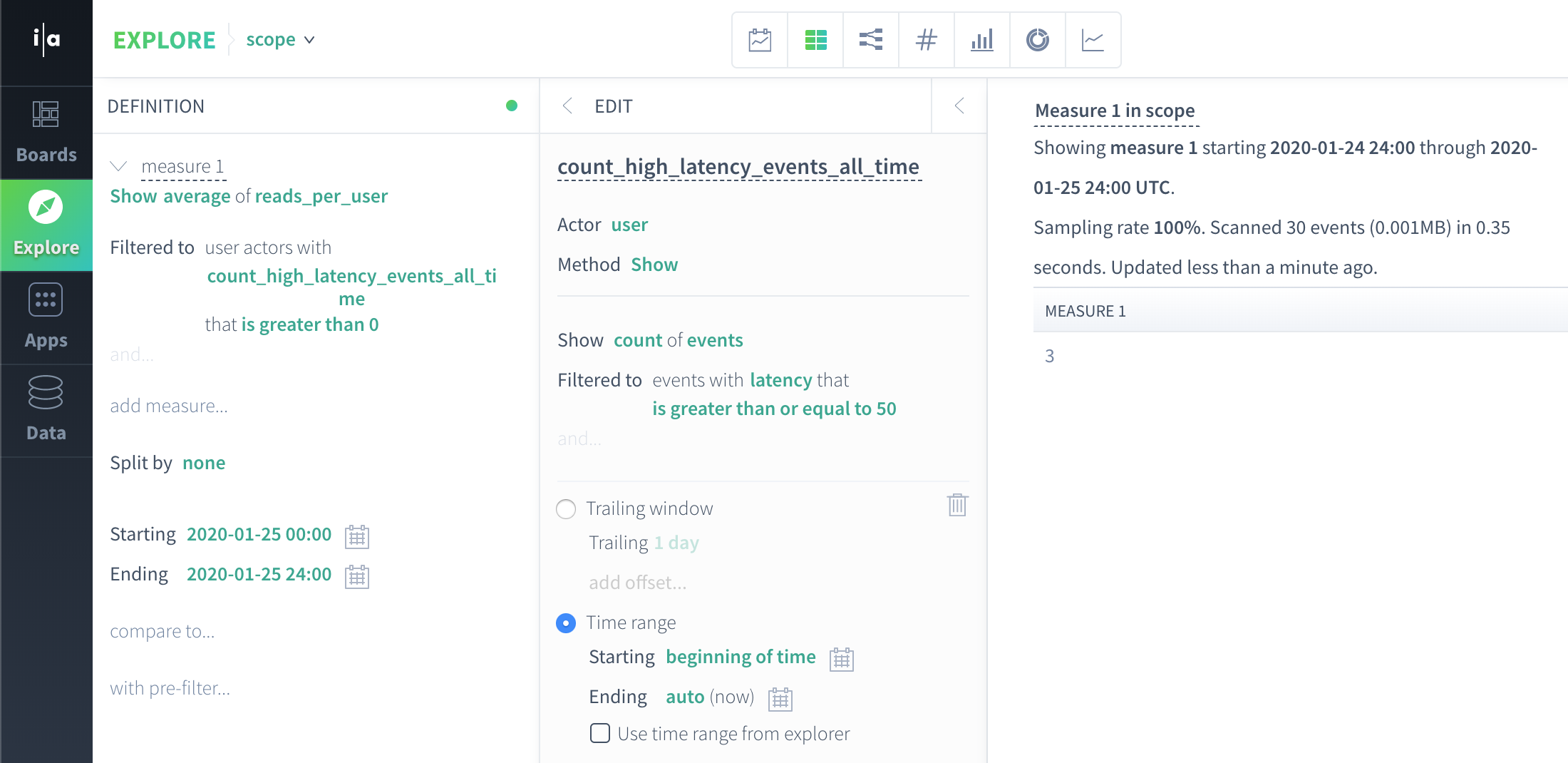
This query executes similarly to the previous query, except the actor properties must be calculated in separate subqueries, since they have different time specs. We still end up with actor scope data that we iterate over to produce the final result. In this case the result is equivalent to the result of the query above, since all events in the dataset are located on 2020-01-25.
Query 3: What is the average per-user read count for users whose median latency over all events on 2020-01-25 >= 50?
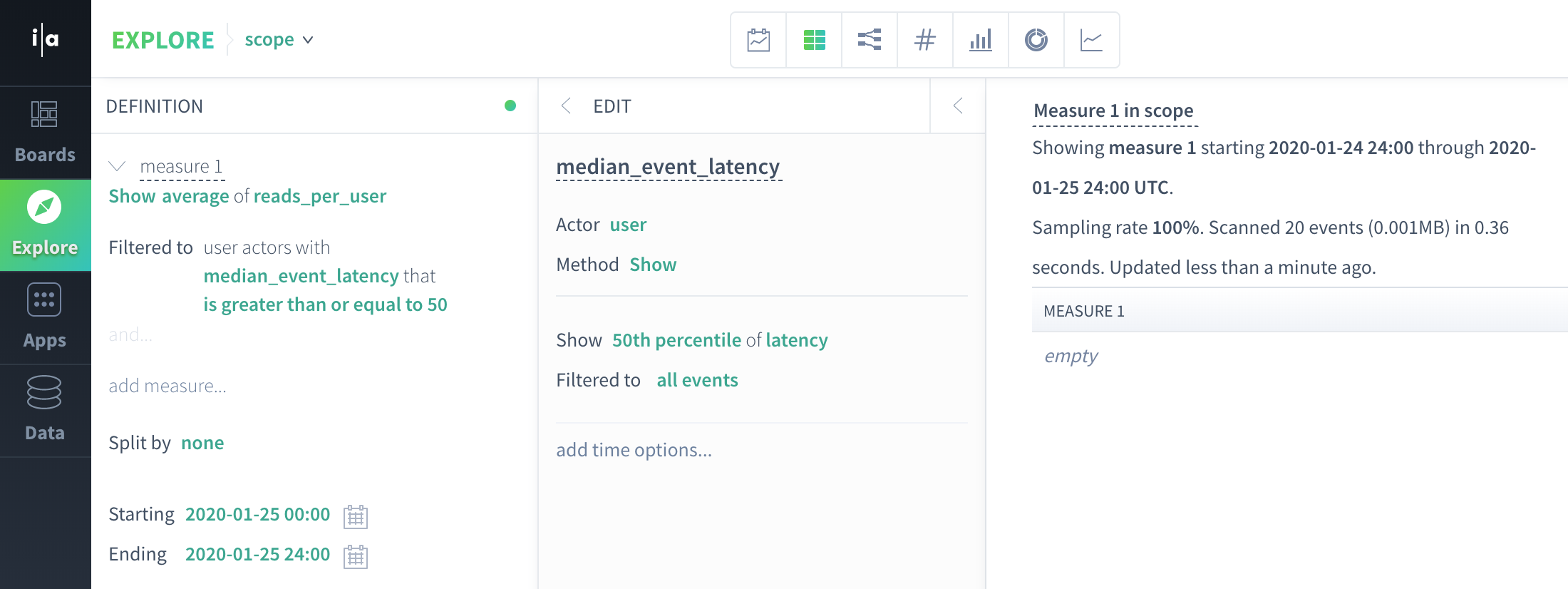
Same general process as Query 1: produce actor scope data from count(reads), median(latency) group by user subquery:
user | reads_per_user | median_event_latency |
John | 1 | 25 |
Anca | 1 | 27 |
Manasa | 3 | 28 |
Since none of our actors match the median_event_latency filter, average(reads_per_user) produces an empty result.
Query 4: What is the average per-user high latency read count on 2020-01-25?
This approach is different, since we modify the existing reads_per_user actor property instead of creating a new actor property.
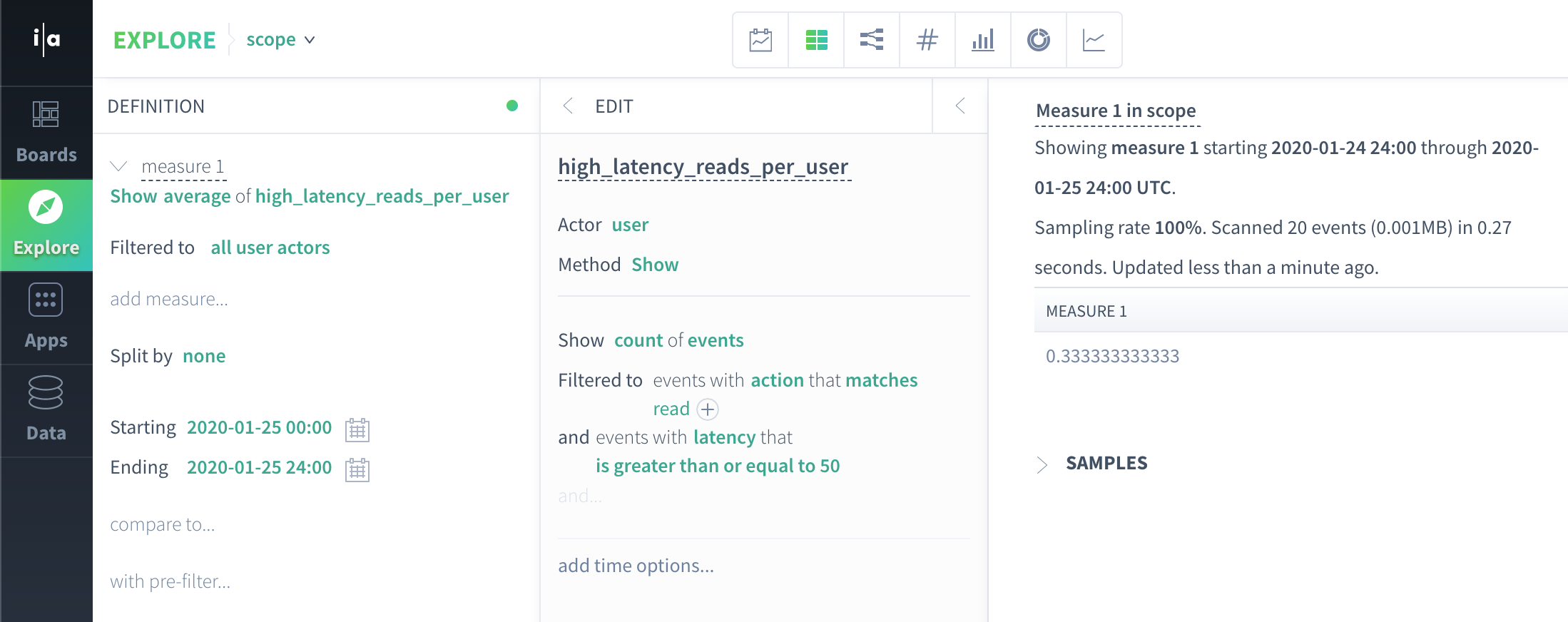
For this approach, we simply modify the definition of reads_per_user to include a filter for latency >= 50. From here, the query is calculated as you would expect an actor scope query to be calculated - we produce actor scope data from a subquery defined by our actor property, and aggregate over that actor scope data.
It is possible to add an event property to an actor scope query in Scuba without manually resolving the scope difference with the methods listed above. The behavior of Scuba in this case is similar to the approach in Query 4 above, in that the actor properties in the query are modified to incorporate the event property. Instead of adding to the filter of the actor property, however, the actor property is actually calculated on a per (user, event property) basis. This allows a consistent behavior for adding event properties to actor scope queries in both filter and split-by, but can produce surprising results if not ready for them. We are currently working on providing a way for users to easily select the behavior that they want when adding an event property to an actor scope query.
Bringing flow properties into actor scope
Bringing a flow property into actor scope is similar to bringing an event property into actor scope in that it is possible for an actor to have multiple values of a flow property for a given time range (if they start multiple flow instances within the time range, for example). It follows that the methods of bringing flow properties into actor scope are similar to the methods used for bringing event properties into actor scope. We can either construct a new actor property that performs an aggregation over flow scope data, or modify an existing actor property to incorporate events associated with a particular flow property.
For instance, we can produce the average read count for users whose total session duration > 2 minutes by creating an actor property that references flow total time:
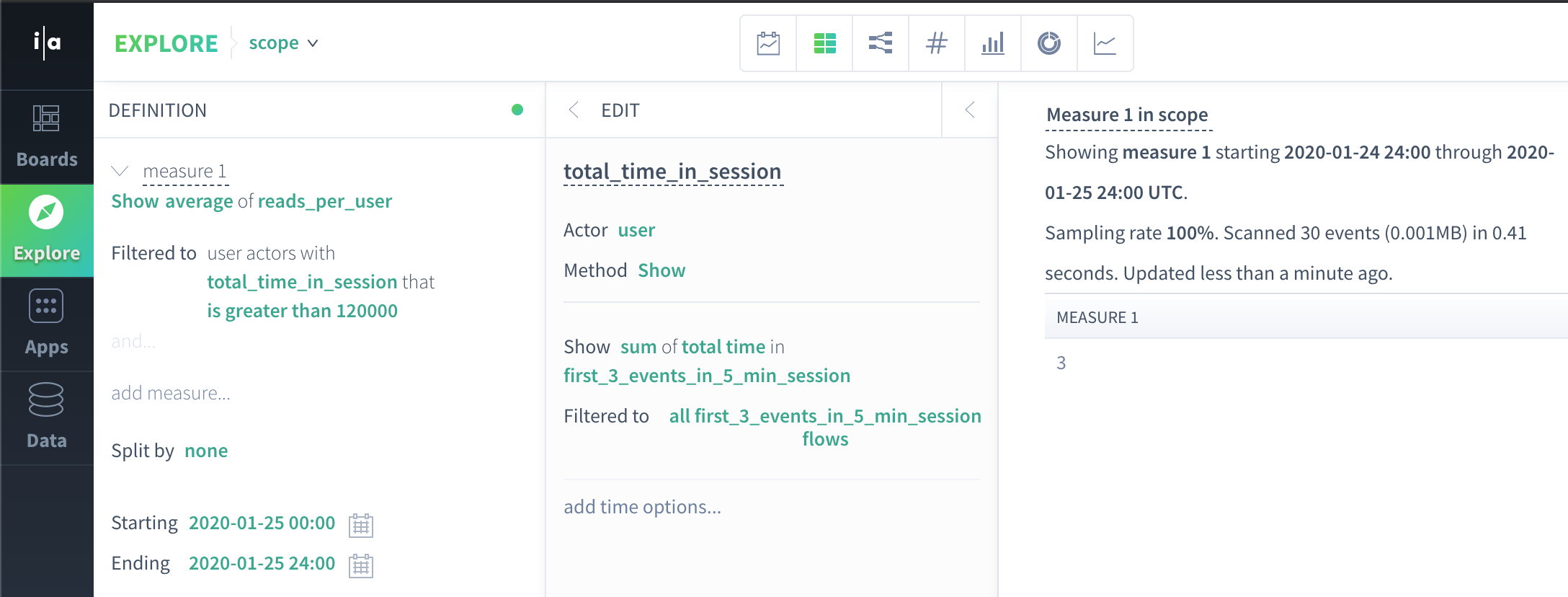
Produce actor scope data from actor property subqueries
user | reads_per_user | total_time_in_session |
John | 1 | 120000 |
Anca | 1 | 120000 |
Manasa | 3 | 152000 |
Filter
user | reads_per_user | total_time_in_session |
Manasa | 3 | 152000 |
Average(3) = 3
Or we could add flow filter to the definition of our reads_per_user actor property:
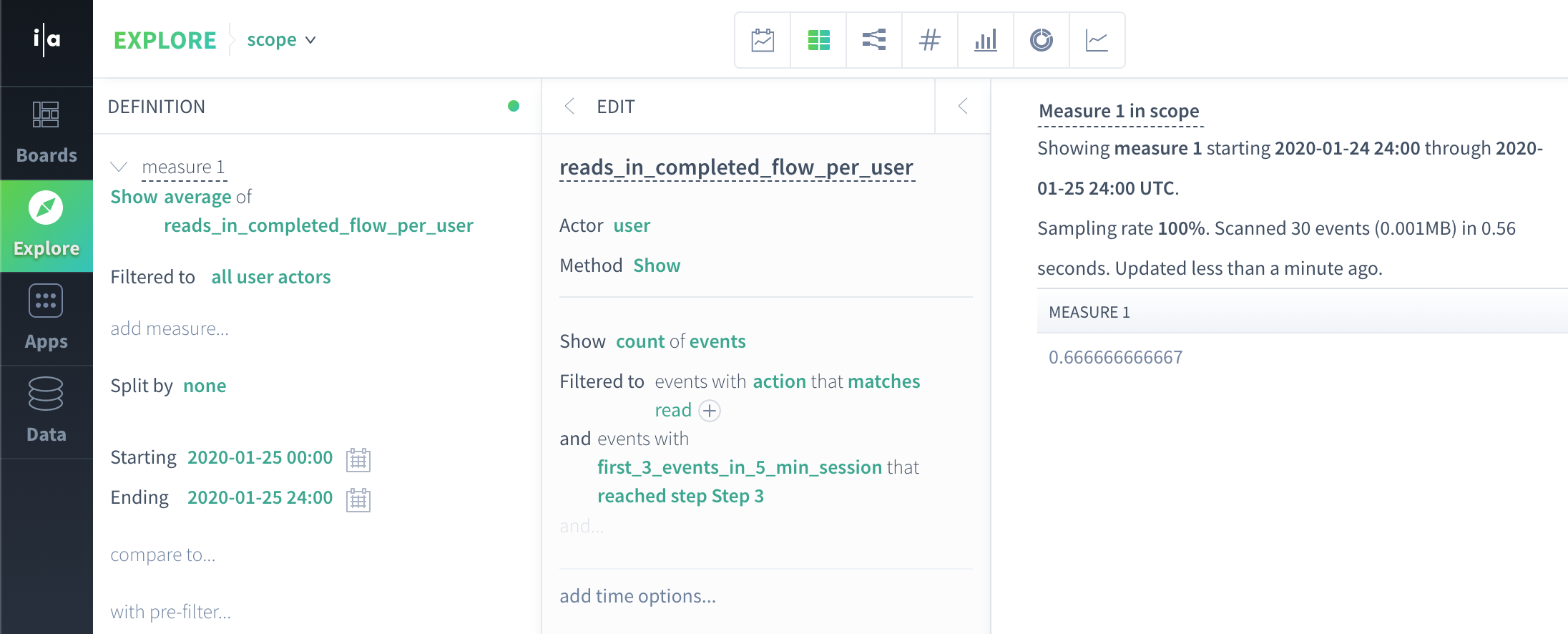
Here our actor property subquery is event scope, so for this filter set to work Scuba will bring the required flow properties into event scope for the actor property subquery. The top level query will be executed over the data:
user | reads_in_completed_flow_per_user |
John | 1 |
Anca | 1 |
Manasa | 0 |
Average(1, 1, 0) = .67
Bringing event properties into flow scope
Bringing an event property into flow scope is similar to bringing an event property into actor scope. The event property can be integrated by either using the event property in a flow property, or altering the definition of the flow itself.
For instance, to filter to flow instances with at least one login event, create a flow property that counts login events per flow instance. This is what the query looks like in the Scuba UI:
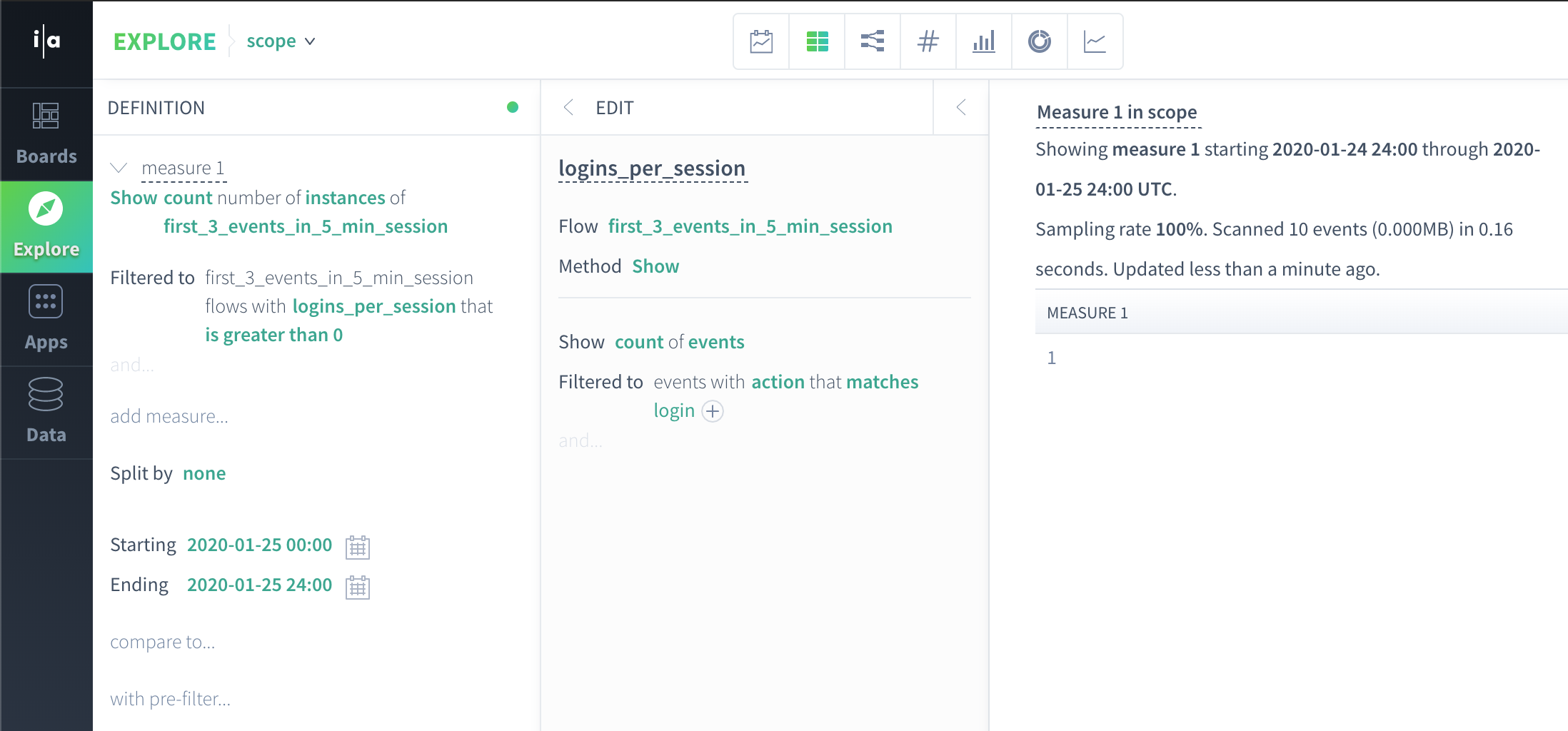
First Scuba produces flow scope data using the flow definition and collect flow scope logins_per_session property:
flow_id | user | logins_per_session |
1 | John | 1 |
2 | Anca | 0 |
3 | Manasa | 0 |
4 | Manasa | 0 |
Filter
flow_id | user | logins_per_session |
1 | John | 1 |
Count(rows) = 1
We could also incorporate event properties directly into the flow definition (note the action matches read filter in the flow definition):
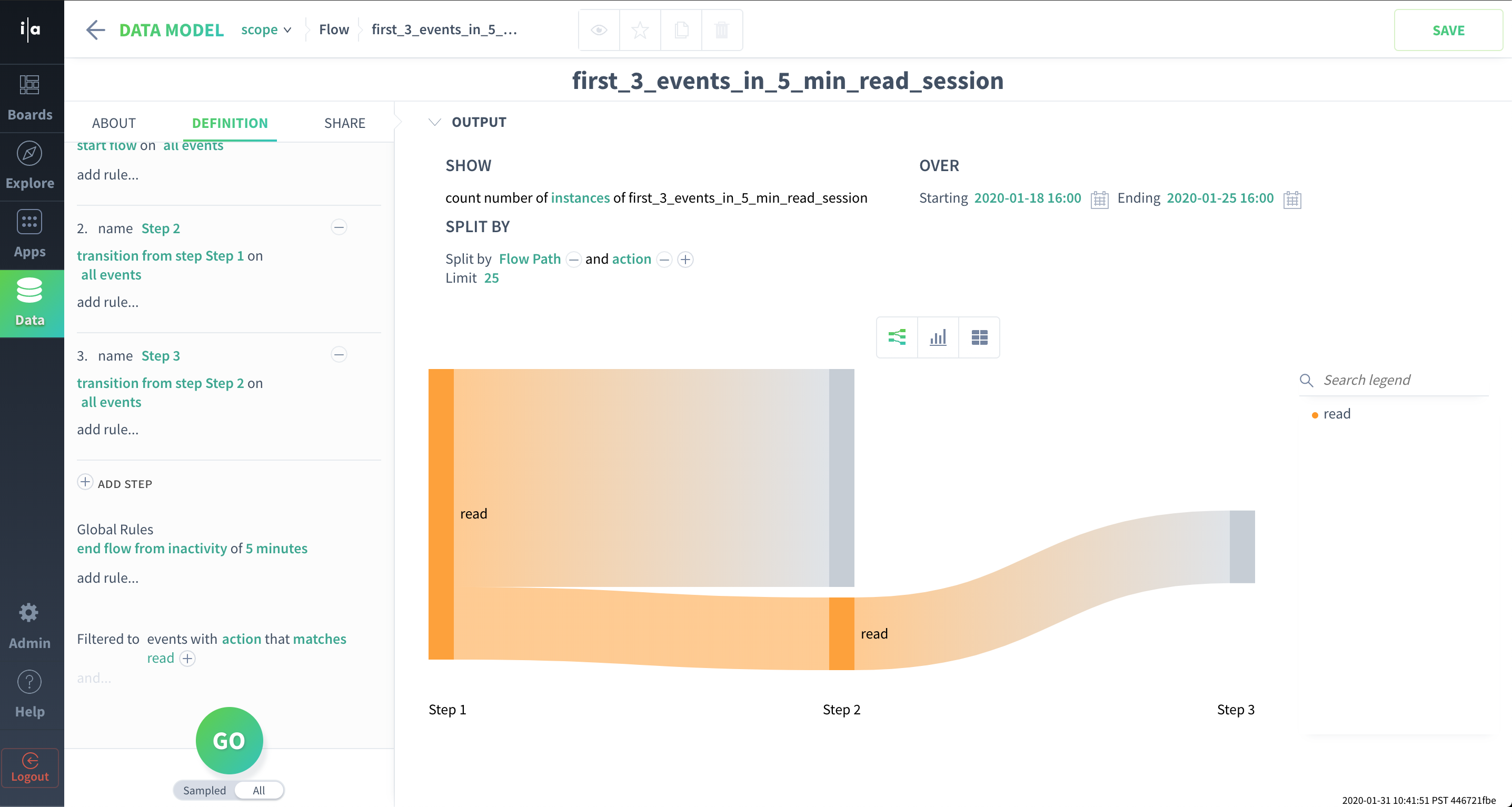
Produce flow scope data using new flow definition that filters to read events only.
flow_id | user | total time in read session |
1 | John | 0s |
2 | Anca | 0s |
3 | Manasa | 60s |
4 | Manasa | 0s |
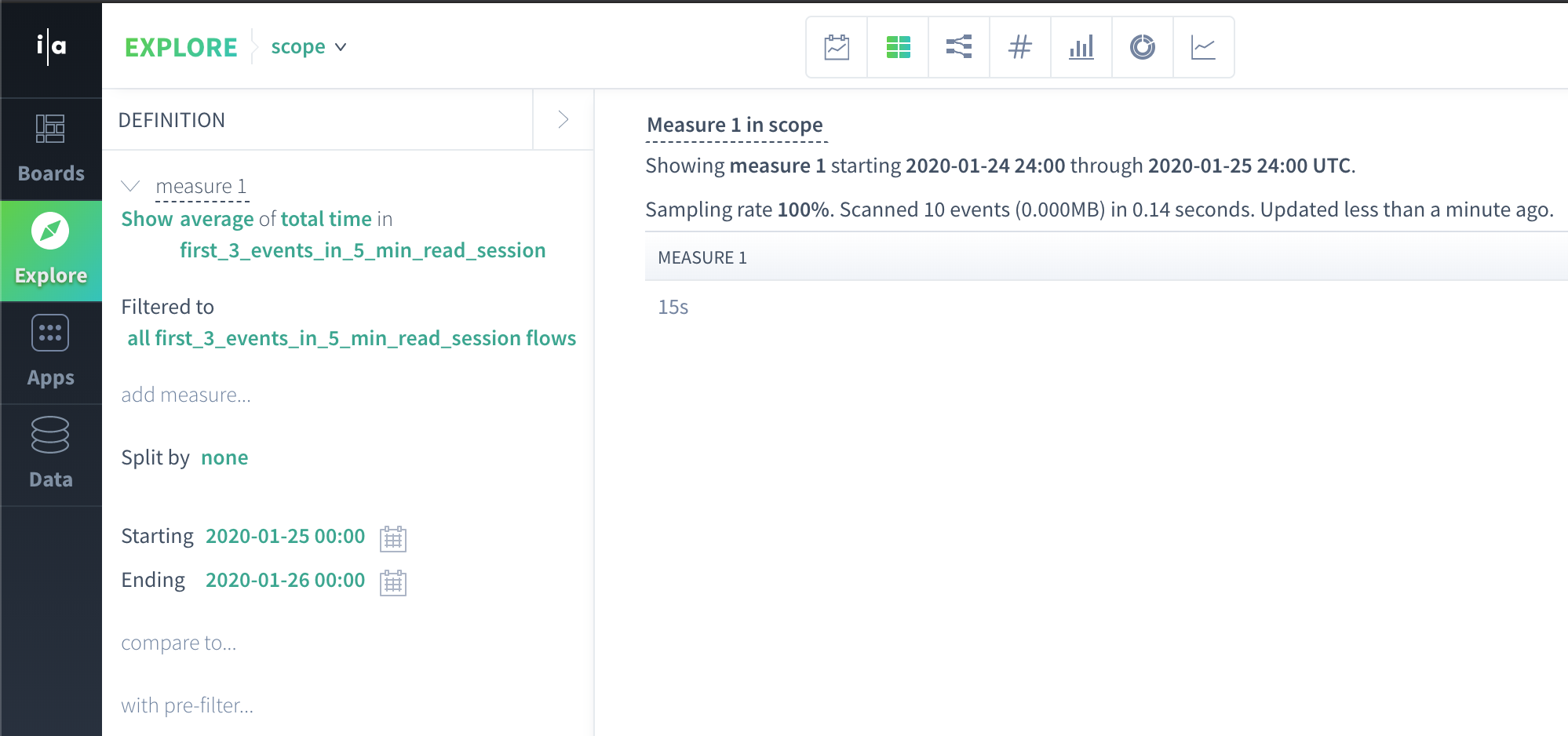
A flow that has only one event has a total time of 0 seconds, since total time = timestamp(last event in flow) - timestamp(first event in flow)
Average(0,0,60,0) = 15s.
Bringing actor properties into flow scope
Bringing actor properties into flow scope works similarly to bringing actor properties into event scope. Since actor data is present in both flow and actor scopes, we can simply left join actor scope data to flow scope.
Here is a Scuba query where this happens:
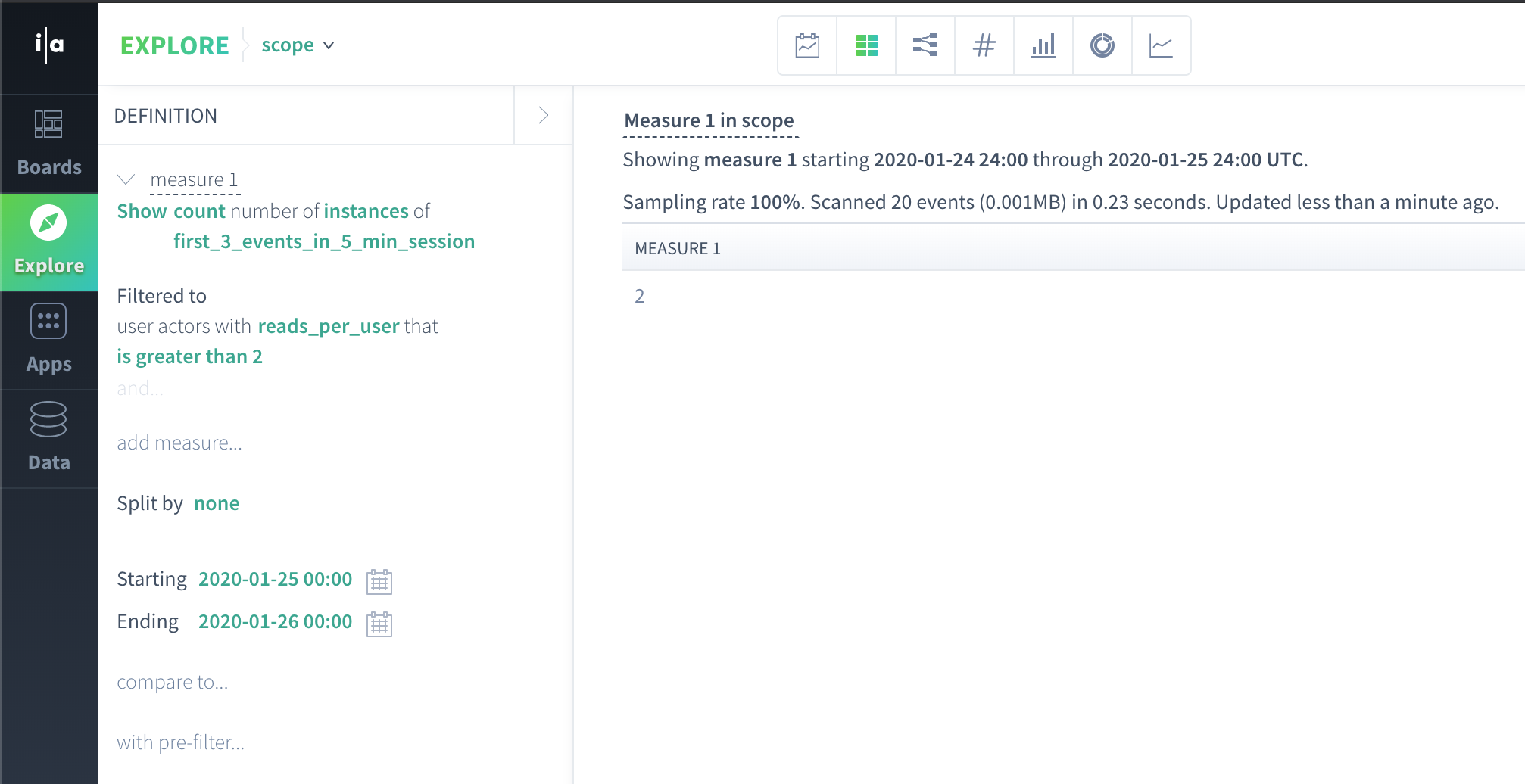
First, we produce flow scope and actor scope data independently:
flow_id | user |
1 | John |
2 | Anca |
3 | Manasa |
4 | Manasa |
user | reads_per_user |
John | 1 |
Anca | 1 |
Manasa | 3 |
Next, left join actor scope data to flow scope data:
flow_id | user | reads_per_user |
1 | John | 1 |
2 | Anca | 1 |
3 | Manasa | 3 |
4 | Manasa | 3 |
Filter:
flow_id | user | reads_per_user |
3 | Manasa | 3 |
4 | Manasa | 3 |
And finally, aggregate:
Count(Rows) = 2