Planning your Scuba deployment
This document offers guidelines for planning a Scuba deployment that meets your company's current data analytics needs, as well as scaled growth for the future.
Note that for most deployments, you will work with a Scuba representative to determine sizing, set up cluster(s), and deploy to production. If this is not the case, please reach out to help@scuba.io to ensure you have access to all necessary Scuba Admin documentation.
Scuba—behavioral analytics for your whole team
Scuba is full stack behavioral analytics software with a web-based visual interface and scalable distributed back-end datastore to process queries on event data.
Scuba's intuitive graphical user interface (GUI) provides interactive data exploration for a wide range of users across the spectrum of digital businesses. The Visual Explorer encourages rapid iteration with point-and-click query building and interactive visualizations. All without having to deal with complicated query syntax. You can go from any board to explore the underlying data, change parameters, and drill down to the granular details of the summary.
To plan a Scuba deployment that is optimized for your company, review the following topics:
High-level overview—how Scuba works
Scuba is full stack behavioral analytics software that allows users to explore the activity of digital services. Scuba includes both its own web-based visual interface and a highly scalable distributed back end database to store the data and process queries. Scuba supports Ubuntu 14.04.x in cloud environments, as well as virtual machines or bare-metal systems. Scuba enables you to ingest data in a variety of ways, including live data streams.
The following image shows an example of the flow of data into the Scuba cluster from imported files (single and batch) to live data streams from HTTP and Kafka sources. Ingested data is transformed and stored in the appropriate node, data or string, then processed in queries, with the results delivered to the requesting user.
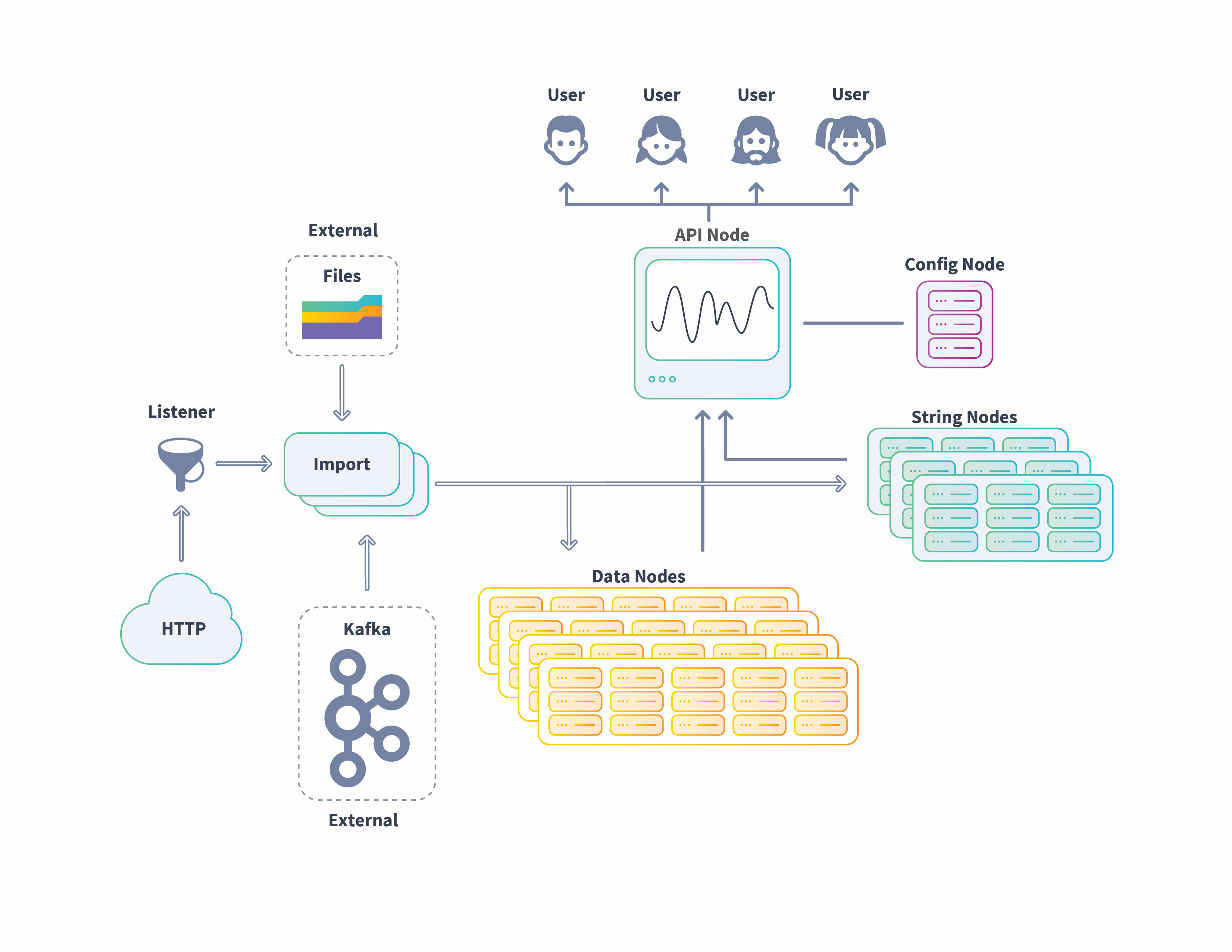
The basics—system requirements
It is important to understand the hardware, software, and networking infrastructure requirements to properly plan your Scuba deployment. Before making a resource investment, read through this entire document. The following sections explain sizing guidelines, data formats, and platform specific information needed to accurately estimate a Scuba production system for your company.
A Scuba cluster consists of the following nodes that can be installed on a single server (single-node cluster), or across multiple servers (multi-node cluster).
config node — Node from which you administer the cluster. MySQL database (DB) is only installed on this node for storage of Scuba metadata. Configure this node first.
api node — Serves the Scuba application, merges query results from data and string nodes, and then presents those results to the user. Nginx is only installed on the API node.
import (ingest) node — Connects to data repositories (cloud, live streaming, remote or local file system), streams live data, downloads new files, processes the data and then sends to data and string tiers, as appropriate.
data node — Data storage. Must have enough space to accommodate all events and stream simultaneous query results.
string node — String storage for the active strings in the dataset, stored in compressed format. Requires sufficient memory to hold the working set of strings accessed during queries.
listener node — Streams live data from the web or cloud, also known as streaming ingest. Only applicable when ingesting from HTTP.
The following table outlines basic software, hardware, and network requirements for a Scuba deployment.
Software | Hardware | Browser | Networking |
|---|---|---|---|
Operating system (OS): Ubuntu 18.04 | Linux desktop and server systems in a private cloud, or locally at your company site. Minimum requirements for each node, unless otherwise noted:
| Microsoft Edge—Latest version Chrome—Latest version |
|
Guidelines for calculating the number of node type for your deployment are covered in the following sections.
Production workflow—test, review, revise, and go
It is strongly recommended that you first set up a sandbox test cluster (or work with your Scuba rep to have one set up for you) with a sample of your data, so any necessary adjustments can be made before deploying a production environment. This will allow you to assess the quality of your data and better determine the appropriate size for a production cluster.
For self-service Scuba deployments, follow these steps:
Review the rest of this document to gain a preliminary assessment of the needs for your production cluster.
Install a single node cluster in a sandbox test environment.
Load a week's worth of data.
Modify your data formats until you get the desired results.
Review the usage for the string and data nodes.
From the usage for one week's worth of data, you can estimate usage for one month, and then one year.
Factor in the estimated growth percentage for your company to create a multi-year usage projection.
Set up your Scuba production environment and ingest your data.
Cluster configurations—the big picture
This section provides an overview of a several typical cluster configurations:
Stacked vs. single nodes
Single-node cluster
Two node cluster
Five node cluster
Ten node cluster
Stacked vs. single nodes
The configuration of your cluster depends on the amount of data you have, its source, and projected growth. To validate the quality of your data and the analytics you wish to perform, we require a sample of your data prior to going into production.
Stacked nodes are not recommended for large event volumes or workloads, or if you are planning to scale your cluster at a later date.
For smaller deployments, it is possible to stack nodes—install multiple services on one system—in the following ways:
API, config, ingest—admin
string, data—worker
Review the following configuration examples and sizing guidelines, followed by data format and platform-specific issues.
Single-node cluster
The stacked single-node cluster is only recommended for sandbox test environments that are used to validate data and assess the requirements for a production cluster.
Two node cluster
The stacked two-node cluster configuration is for deployments with very low data volumes. In this configuration, the API and config nodes are stacked on the same node. A Listener node for streaming ingest from a live data source is not included, as this tier is optional.
Five node cluster
The following is an example of a basic five node cluster configuration, in which each functional component is installed on a separate system. A Listener node for streaming ingest from a live data source is not included, as this tier is optional.
Ten node cluster
The ten node cluster configuration illustrates how to scale a cluster for increased data capacity with added data and string nodes. To increase disk capacity, it is recommended that you scale the cluster horizontally to maintain your original performance.
Sizing guidelines—for today and tomorrow
Determining the appropriate Scuba cluster size for your company is largely based on the quantity of daily events that are generated. First, determine the current number of generated events, then estimate your company's projected data growth over a year, then multiply by the number of years in your expected growth cycle.
Consider the following when planning the size and capacity of your production Scuba cluster:
Node configurations
Capacity planning
Planning the data tier
Planning the ingest tier
Planning the string tier
Cluster configuration guidelines
Node configurations
The following table provides guidelines for Scuba cluster node configurations.
Component | Recommended configuration | Open ports across the cluster |
|---|---|---|
Data nodes (#) |
| 8500, 8050, 7070 |
Import nodes (#) | An import node can be deployed on its own for intensive ingest requirements, or co-located (stacked) with other nodes (such as a data node) for optimal performance.
| 8500, 8600, 8000 |
String nodes |
| 8050, 2000-4000 |
API node | 60 GB disk space (per CPU Core) The API node includes the following:
The API node can be deployed on its own, or stacked with the config node. | 80, 443, 8600, 8200, 8050, 8500, 8400 |
Config node | 60 GB disk space (per CPU Core) The config node can be deployed on its own node or stacked with the API node. | 3306, 8050, 8700 |
Listener node (optional) | Manages streaming ingest, live data (data-in-motion) from a web or cloud source. The three streaming ingest utilities (Listener, Kafka, and Zookeeper) can be deployed separately or on a single node. | 2181, 2888, 3888, 9092 |
Capacity planning
Use the following guidelines to estimate the capacity for a Scuba production cluster.
Resource | How to calculate capacity |
|---|---|
CPU | Billions of events / number of cores per data node |
Storage | Bytes per event x number of events / available disk per data node |
Memory | Memory = 0.35* disk requirements (for half the events in memory) |
Data nodes (#) | Max (disk, CPU, memory) |
Ingest nodes (#) | Number of data nodes / 4 during bulk import, then 1 after. |
String nodes | Number of data nodes / 4, rounded to the closest odd number. Use 3 to 5 string nodes. Do not use less than 3. It is recommended that you use SSD storage for the string nodes. Bytes per event can be computed after importing a sample of data. 40 is a conservative estimate. |
Planning the data tier
The main constraint for a data tier is disk space. However, beware of under-provisioning CPU and memory resources as it can result in reduced performance. Consider the following guidelines when planning a production data tier:
CPU | Memory and Disk Space |
|---|---|
The number of rows and columns in a table directly affects performance. All columns matter, even if they are not utilized. Prior to importing data, omit columns that are not used. If you have excessively large tables, consider increasing the CPUs of the data nodes. Read performance scales linearly in proportion with the number of CPU cores. | A good estimate is that a data set with 1B events fits in 25 GB memory. Memory increases and scales linearly in proportion with the number of events and nodes. Scuba compression rate is approximately 15-20x (raw data bytes to bytes stored on data servers). DO NOT store data on the root partition. AWS—Use either an ephemeral drive (SSD) or separate EBS volume to store data. A minimum GP2 is recommended. Azure—Use premium local redundant storage (LRS) |
For older generation CPUs, 8 MB of L3 cache is the required minimum. Pre-2010 CPUs are not supported.
Planning the import tier
Consider the following guidelines when planning a production import (ingest) tier:
Capacity | Sizing |
|---|---|
50 GB of raw data / hour / core is a conservative estimate. A single 8 core import node is sufficient in most instances. SSDs are recommended. | 1 import node per 4 data nodes is recommended, in general. You can add ingest nodes to accommodate bulk imports, then remove the extra nodes after the bulk import is done. Performance scales linearly with the number of nodes. |
Beware of over-provisioning. If the data or string tiers are over capacity, the ingest nodes can be affected causing a drop in performance.
Planning the string tier
Consider the following guidelines when planning a production string tier:
Capacity | Sizing |
|---|---|
String columns typically have a lot of duplicates, but are stored only once, verbatim. High-cardinality string columns impede performance, so it's fine to omit duplicate columns. | The main constraint is the disk space. SSDs are strongly recommended. An odd number of string nodes is required. Use 3 or 5 such instances and keep an eye on the disk usage. |
Cluster configuration guidelines
It is recommended that you follow the production workflow, and first deploy a sandbox test cluster with sample data to properly assess your data and accurately estimate a production cluster.
Use the following guidelines in planning your cluster:
For a sandbox test cluster, start with one main dataset on the cluster, with 1 shard key. A separate table copy is required for each shard key. This means that if you want N shard keys for your dataset, you need N times the storage on your data tier. Defining the appropriate number and type of shard keys may be an iterative process for your production cluster. It is recommended that you start small and add additional shard keys as necessary, since each shard key requires a full copy of the dataset.
Log data usually ranges from 50 - 150 bytes / event (storage required for 1 compressed event on the data tier). 80 bytes / event is a reasonable density estimate. High cardinality integer data, such as timestamps and unique identifiers and set columns, take up the most space in a dataset. If your data contains a lot of this type of data, estimate a few more data nodes for your production deployment.
String data should be stored efficiently. The following estimates account for data with several high cardinality string columns: 1 or 2 parsed URL columns, 1 user agent column, and 1 IP address column. Hex identifier columns should be stored as integers, through the use of a hex transform (applied by default in Scuba). Other "string" identifiers (like base64 encoded session ids) are hashed into integers and stored on the data tier.
Consider your expected data retention and adjust the configuration accordingly. You will need more data nodes for a 90-day retention than for 30 days.
Data input volume is another factor to consider when planning a cluster. For instance, a single-node cluster which has a total capacity of 24B events is adequate for 267M (24B / 90D) events per day. To import a higher volume of events per day, larger import and data tiers are required to keep up with the ingest rate and service queries in a timely manner.
Data types and formats—consider your source
It's important to consider the source of your data, as well the data type and how it's structured. Streaming ingest requires a special cluster configuration and installation. Be aware that some data types may require transformation for optimum analytics.
Data types
Scuba accepts the following data types:
JSON—Scuba's preferred data format. The JSON format is a flat set of name-value pairs (without any nesting), which is easy for Scuba to parse and interpret. If you use a different format, your data must be transformed into JSON format before it can be imported into Scuba.
Apache log format—Log files generated using mod_log_config. For details, see mod_log_config - Apache HTTP Server Version 2.4. It's helpful to provide the mod_log_config format string used to generate the logs, as Scuba can use that same format string to ingest the logs.
CSV—Scuba accepts CSV format with some exceptions. First, ensure sure you have a complete header row. Next, ensure you are using a supported separator character (tab, comma, semicolon, or ascii character 001). Finally, ensure your separator is clean and well-escaped—for example, if you use comma as your separator, make sure to quote or escape any commas within your actual data set.
For more information, see the Data types reference. For best practices in logging your data, see Best practices for formatting your data.
Data sources
Scuba can ingest event data a variety of ways:
Amazon Simple Storage Service (S3)—Cloud storage (Amazon Web Services, AWS)
Microsoft Azure—Blob storage
Google Cloud Platform—Unified object storage
Live data on an HTTP port—Streaming ingest
Local file systems—See the Ingest file types and formats reference
Logging and adding data
How your data is structured is important for optimum analytics results and performance. Review the following topics:
Platform-specific planning—how much is enough?
The following table compares system recommendations for cluster configurations on the following platforms:
On-premise installations should only use local SSDs, no Storage Area Networks (SAN).
The Azure recommendations in the following table allow you to add premium storage.
Configuration | System recommendation |
|---|---|
Single-node: 1 node, 4 CPU, 8 GB memory | AWS—i3.xlarge or m5.xlarge, Azure—DS3_V2 |
Stacked nodes: 2 nodes, 4 CPU, 16 GB memory | AWS:
Azure: DS3_v2 Blob Storage is different between the 2 nodes:
|
Small multi-node: 4 nodes, 4 CPU, 64 GB memory | Depends on the stacked configuration, but in general the following configurations are recommended. AWS:
Azure:
|
Larger multi-node: 10 nodes, 4 CPU, 800 GB memory | AWS:
Azure:
|